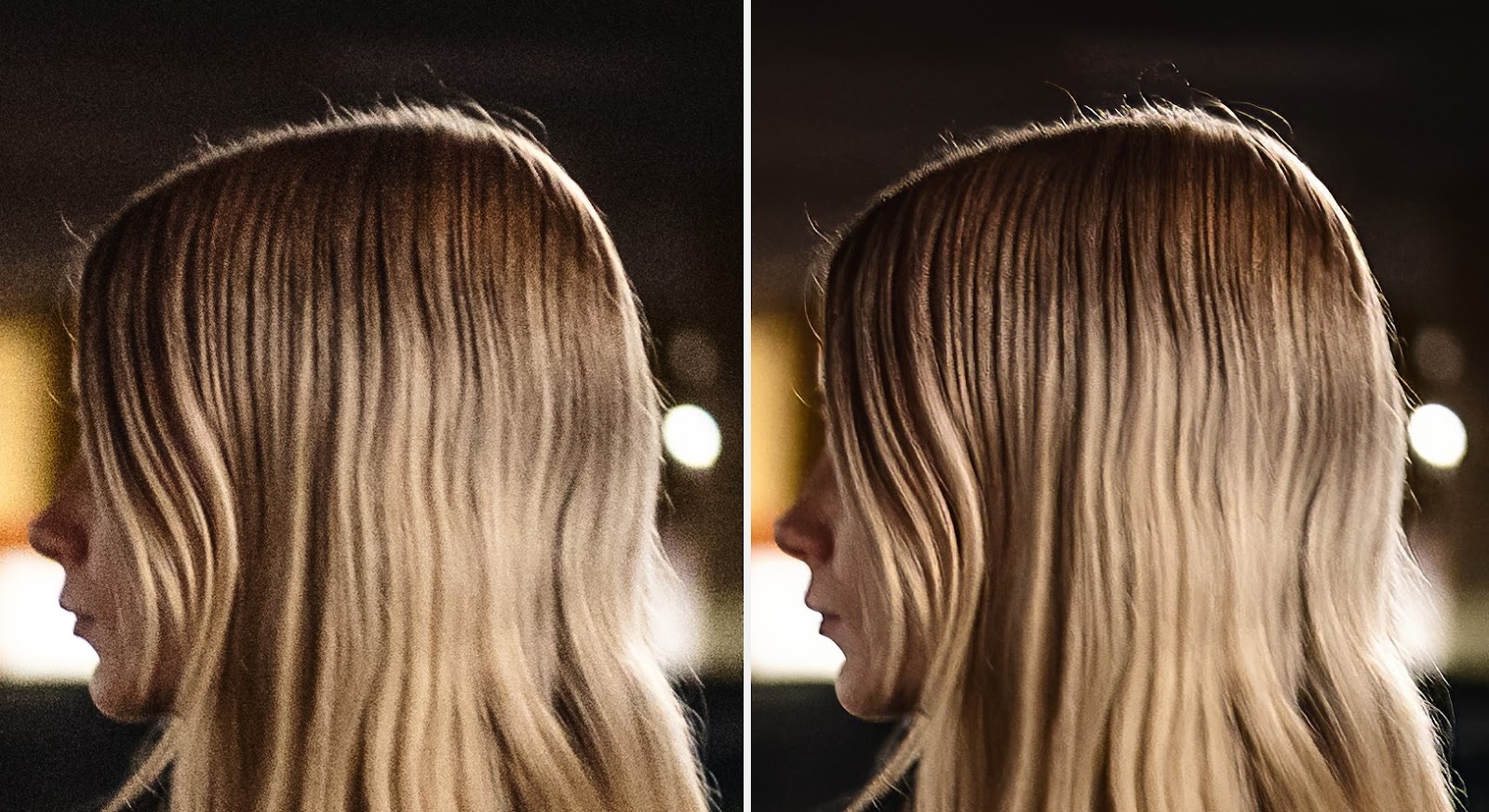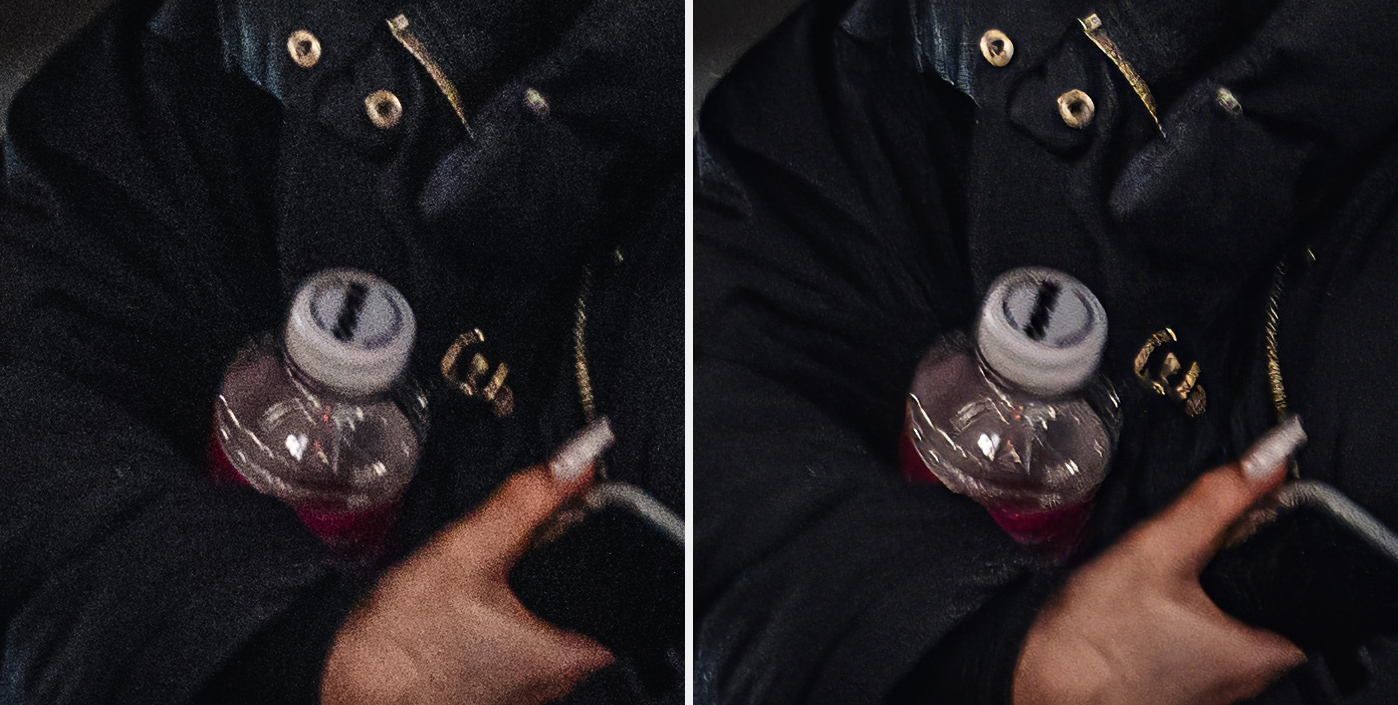Hejson!
Dzisiejsza konsumpcja mediów ma to do siebie, że odbywa się na 5-6 calowym ekranie telefonu. Ma też to do siebie, że zanim zdjęcie dotrze do Ciebie, to przejdzie przez 6 konwersacji na jedynym słusznym messengerze, zatem zostanie 6-cio krotnie skompresowane. W międzyczasie, jak będziecie mieli pecha, to jakiś wujek zrobi screena, zamiast zapisać zdjęcie w oryginalnej rozdzielczości, wówczas źle wygląda już na pierwszy rzut oka. Jakiekolwiek kadrowanie czy chęć wydruku zdjęcia obnaża pliki,z jakimi próbujemy dokonać takich manewrów. Zatem słowo klucz: upscaling.
Jednym z podstawowych algorytmów stosowanych w super-rozdzielczości jest konwolucyjna sieć neuronowa (CNN). Modele CNN wykorzystują konwolucje, które polegają na przetwarzaniu obrazu za pomocą filtrów wyodrębniających cechy charakterystyczne. Zasadniczo, model SR (Super Resolution) bazuje na wielu warstwach konwolucyjnych, które uczą się wydobywać coraz bardziej skomplikowane struktury obrazu. Dzięki procesowi uczenia nadzorowanego, sieć jest w stanie rozpoznać wzorce i zależności, które prowadzą do rekonstrukcji obrazu o wyższej rozdzielczości.
Popularnym podejściem do super-rozdzielczości jest zastosowanie generatywnych sieci kontradyktoryjnych (Generative Adversarial Networks). GAN składają się z dwóch rywalizujących sieci: generatora, który próbuje wygenerować obraz o wyższej rozdzielczości, oraz dyskryminatora, który ocenia, na ile generowany obraz jest realistyczny. Podczas treningu oba komponenty dążą do wzajemnego doskonalenia się, co prowadzi do uzyskania wyjątkowo szczegółowych wyników. Przykładem modelu wykorzystującego tę metodologię jest ESRGAN (Enhanced Super-Resolution Generative Adversarial Network), który wyróżnia się wysoką jakością detali oraz naturalnością tekstur.
Równie istotnym podejściem są modele oparte na transformatorach, takie jak SwinIR (Swin Transformer for Image Restoration). Zastosowanie architektury transformatorowej pozwala modelowi na efektywne przetwarzanie kontekstowych zależności pomiędzy różnymi obszarami obrazu. Transformator Swin, poprzez swój mechanizm samouwagowy (self-attention), umożliwia lepsze uchwycenie relacji długozasięgowych, co jest szczególnie korzystne przy rekonstrukcji szczegółów w obrazie o podwyższonej rozdzielczości.
Innym ciekawym aspektem jest wykorzystywanie tzw. uczenia resztowego (residual learning), które pomaga w efektywnej nauce modeli SR. Sieci resztowe uczą się rekonstruować różnicę pomiędzy obrazem o niskiej rozdzielczości a jego wersją o wysokiej rozdzielczości, co przyspiesza proces konwergencji modelu. Technika ta jest często stosowana w połączeniu z głębokimi sieciami konwolucyjnymi, takimi jak VDSR (Very Deep Super Resolution), które osiągają znakomite rezultaty pod względem jakości i szybkości.
Przystosowanych do tego modeli i narzędzi jest wiele. Osobiście korzystam z płatnego rozwiązania od Topaz Labs. Kiedyś aplikacje podzielone były na Denoise, Sharpener, Gigapixel etc., dziś spakowane jest to do jednego programu. Wykorzystam zatem zdjęcie z poprzedniego tekstu, niepodpisanego autora.
Oryginalny plik ma rozdzielczość 910×1370. Not great, not terrible. Na pewno nie jest to rozdzielczość, która satysfakcjonowałaby mnie do dalszego działania ze zdjęciem. Program pozwala na maksymalnie 6-cio krotne zwiększenie rozdzielczości obrazu. Do wyboru mamy kilka modeli, w zależności od potrzeb. Prawdopodobnie większość klientów będzie zainteresowana poprawą jakości zdjęć przedstawiających bliskich i ich samych, zatem największy nacisk położony został na face recovery, który to działa bardzo satysfakcjonująco i, niestety, bardzo często odstawia jakościowo pozostałą część kadru. Wówczas, osobiście, wchodzę do Photoshopa i łączę kilka zdjęć w jedno, spójne… Tak, jestem zapaleńcem i zwolennikiem quality contentu.
Ale odchodząc od moich zboczeń, tak prezentuje się obraz wyjściowy.

Staram się też dosyć ostrożnie obcować z suwakami, żeby zminimalizować sztuczność efektu.



Dużym wyzwaniem, ponownie, są kosmyki włosów. Tutaj do gry dołącza funkcja face recovery, która ma za zadanie urealnić twarz, zebrać z niej niepotrzebne przeostrzenie, jednocześnie dodając sztuczne rozmycie, aby ów twarz wyróżnić na zdjęciu. To, tak jak suwaki Minor Denoise/Deblur, powodować może nieprzyjemne artefakty i każde zdjęcie wymaga po prostu licznych prób i przybliżeń.

Teraz na tapet weźmy moje stare zdjęcie krajobrazowe. Oryginalna rozdzielczość to 1080×720.

Tak prezentuje się przybliżenie na budynek i fragment natury:


A tutaj woda:

I na koniec przykład dosyć hardkorowy: zdjęcie które poczyniłem kilka lat temu telefonem HTC 10, z oryginalnej rozdzielczości 3984×2241, przeskalowane do 640×360. Porównamy zatem Upscale do oryginału.
Wycinki przedstawiają odpowiednio: plik bardzo mocno skompresowany, plik oryginalny, model standard oraz model high fidelity.

Tak wygląda bokeh, czyli okrągle rozmycia punktów światła.

Dla zaspokojenia potencjalnej ciekawości, pokażę Wam działanie funkcji wyostrzania i odszumiania zdjęć. Przed/po: